ML Model Deployment
Why Deployment: ML in production vs. ML in research
These are important for ML in production than in research:
- stakeholder involvement
- computational priority
- the properties of data used
- the gravity of fairness issues
- the requirements for interpretability
Workflow for Deploying ML Models to Production
- 1. Environment & Permissions Setup
- Prepare secure infrastructure for data, training, and deployment.
- Common tools:
- Identity: RBAC, IAM, OAuth
- Storage: S3 / GCS / Azure Blob / MinIO / NFS
- Networking: VPC, VPN, Firewall, TLS/SSL, Private Subnets
- Secrets: Vault, AWS Secrets Manager, GCP Secret Manager
- 2. Data Ingestion + Feature Pipeline
- Collect, clean, transform & store training data.
- Common Tools:
- Batch: Airflow, Spark, Snowflake, BigQuery, Redshift, Lakehouse
- Streaming (optional): Kafka, Flink, Spark Streaming, Pulsar
- Feature Store: Feast, Hopsworks, Tecton, Amazon SageMaker Feature Store
- 3. Model Training + Tuning
- Train and tune the model with reproducible tracking.
- Common Tools:
- Frameworks: PyTorch, TensorFlow, JAX, Scikit-Learn, XGBoost
- Orchestration: Kubeflow, Airflow, MLflow, Vertex Pipelines, Azure ML, Amazon SageMaker
- HPO: Optuna, Ray Tune, Hyperopt, Katib
- 4. Model Evaluation + Versioning
- Validate performance & version models.
- Common Tools:
- Experiment + Registry: MLflow, DVC, Neptune, Weights & Biases
- Evaluation metrics + fairness/robustness testing
- Assign model versions + metadata
- 5. Model Serving + Deployment: [[#ML Deployment Approaches]]
- Make the model accessible for inference.
- Options:
- Managed Cloud Endpoints (Amazon SageMaker/GCP/Azure ML)
- Containerized Services (Docker + Kubernetes)
- Inference Servers (Triton, TorchServe, TF Serving)
- Serverless (Lambda/Cloud Functions: low-volume usage)
- Edge/Mobile (TFLite, CoreML)
- 6. API Layer (Client-Facing): [[#Model Serving Tooling]]
- Common Tools:
- Web serving: FastAPI, Flask, Django, gRPC
- Load balancing: Kubernetes Ingress, Envoy, NGINX, ALB, CloudFront
- Common Tools:
- 7. Security, Scaling & Optimization: [[#Accelerating ML Model Inference]]
- Ensure performance, scale, safety, cost efficiency (see [[#Performance metrics]])
- Common Tools: AWS API Gateway, AWS Lambda (AWS for Data Science#^94aba2), AutoScaling
- 8. Application Integration
- Attach the model to real products & systems.
- Possible Clients: Web apps, mobile apps, dashboards, IoT, backend services
- Common Tech Stack:
- Web: React, Vue, Next.js
- Backend: Node.js, Flask/FastAPI, Spring Boot
- Databases: Postgres, MongoDB, DynamoDB, Redis cache
- 9. CI/CD + Model Lifecycle Automation
- Continually update models & push new versions safely.
- Common Tools:
- CI/CD: GitHub Actions / GitLab CI / Jenkins / ArgoCD
- Automated retraining: Airflow, Kubeflow, Amazon SageMaker Pipelines
- Deployment strategies: Canary, Blue-Green, Shadow Deploy
- 10. Monitoring, Drift Detection & Maintenance: ML System Monitoring and Continual learning
- Prevent silent model degradation.
- Common Tools:
- Logging: ELK Stack, Grafana, Prometheus, OpenTelemetry
- Monitoring: MLflow monitoring, WhyLabs, Arize AI, Fiddler, Amazon CloudWatch
- Drift detection: EvidentlyAI, River, Alibi Detect
Model Serving
Serving = making your model available for real users to query through an API or endpoint.
Key components
- model file
- an interpreter / runtime (TF Serving, ONNX Runtime, TorchServe, custom Python code)
- input/output interface (API, CLI, streaming consumer)
Performance metrics
- latency = the time it takes from receiving a quest to returning the result
- throughput/successful request rate = how many queries are processed within a specific period of time
- cost: for compute resources (CPU, etc.)
Balancing metrics
- Higher throughput + lower latency usually → higher cost
- Ways to balance:
- reducing costs by GPU sharing
- multi-model serving
- optimizing models used for inference
- autoscaling / adaptive batching
Model Serving Tooling
Web/API Frameworks for Model Serving
What is an API
- An API lets two pieces of software talk to each other using the client/server architectural style. It allows programmatically accessing some data or perform some action.
- In ML, clients send input → server returns prediction.
REST API
REST = Representational State Transfer
- two components: request and response
- They enable you to communicate using the internet, taking advantage of storage, greater data access, artificial intelligence algorithms, and many other resources.
- e.g. web service inputs into client via API; API outputs data into client
- Common API endpoints
- GET: retrieves some data
- POST: sends some data to create something and receive a response
- PUT: sends data to update something that already exists
- DELETE
API Frameworks for Serving Models
| Framework | Notes |
|---|---|
| FastAPI | Best for high-performance async inference |
| Flask | Simple + flexible |
| Django | Full web framework, includes ORM and auth |
| gRPC (non-REST) | Faster binary communication, used in high-load inference |
Specialized Serving Platforms
- TensorFlow Serving
- TorchServe
- NVIDIA Triton Inference Server
- Cloud Provider Solutions
ML Deployment Approaches
- Cloud deployment – AWS/GCP/Azure managed inference endpoints
- Containerization – Docker + Kubernetes
- Dedicated servers – TensorFlow Serving, ONNX Runtime, TorchServe
- Serverless – AWS Lambda (AWS for Data Science#^94aba2), Cloud Functions (low-maintenance, pay-per-request)
- Mobile / Edge deployment – CoreML, TFLite, ONNX Edge
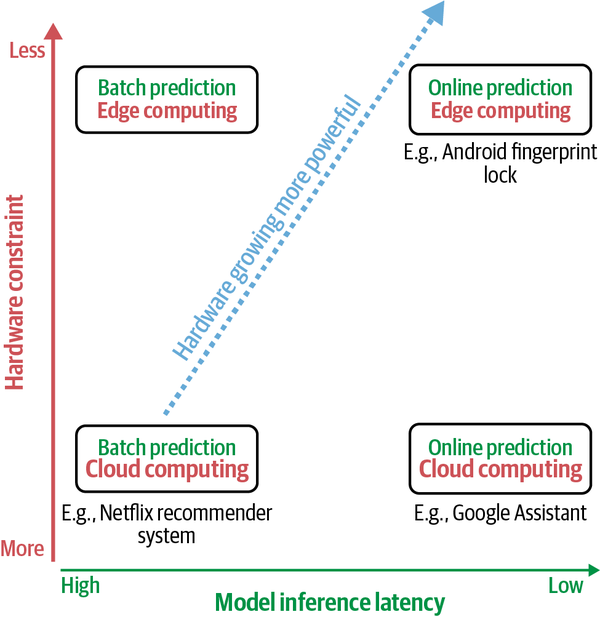
Prediction Modes
Batch Prediction VS. Online Prediction
| Batch Prediction (asynchronous) | Online/Real-Time Prediction(synchronous) | |
|---|---|---|
| Trigger | Scheduled / periodic | Predict-per-request |
| Best for | Processing accumulated data when you don’t need immediate results: Recommender refresh, bulk scoring, churn prediction | When predictions are needed as soon as a data sample is generated: Fraud detection, chatbots, personalization |
| Optimized for | High throughput | Low latency |
| Cost model | Pay during batch jobs | Pay while endpoint is active |
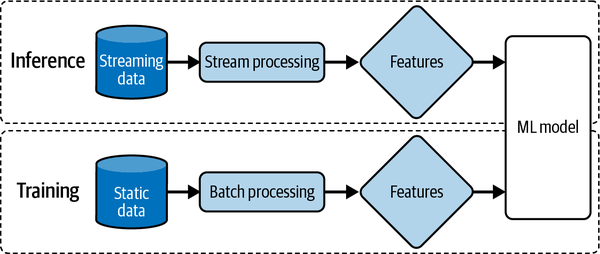
Unifying Batch Pipeline and Streaming Pipeline
Nowadays, the two pipelines can be unified by having two teams:
- the ML team maintains the batch pipeline for training
- the deployment team maintains the stream pipeline for inference
Accelerating ML Model Inference
There are three main approaches to reduce its inference latency:
Model Optimization (compute faster)
- Vectorization
- Parallelization: Given an input array (or n-dimensional array), divide it into different, independent work chunks, and do the operation on each chunk individually
- Loop tiling: Change the data accessing order in a loop to leverage hardware’s memory layout and cache
- Operator fusion: Fuse multiple operators into one to avoid redundant memory access
Model Compression (smaller weights)
- low-rank factorization
- replace high-dimensional tensors with lower-dimensional tensors
- knowledge distillation
- a method in which a small model (student) is trained to mimic a larger model or ensemble of models (teacher)
- pruning
- originally for decision trees (Decision Tree & Random Forest#^4c01d0)
- now also mean reducing the extra parameters in neural networks
- quantization
- reduces a model’s size by using fewer bits to represent its parameters. e.g representing a float number using 32 bits instead of 16 bits (FP32 → FP16/INT8)
- most general and commonly used model compression method
Hardware Strategies
make the hardware it’s deployed on run faster
- Cloud inference (scalable GPU/TPU compute) = a large chunk of computation is done on the cloud, either public clouds or private clouds
- Edge inference (runs on-device: mobile, IoT) = a large chunk of computation is done on consumer devices
- hybrid: precompute on cloud + fast local inference: need powerful hardware